正在下载:sys_antidebug_crack.zip 看雪CTF2017学习记录整理系列3
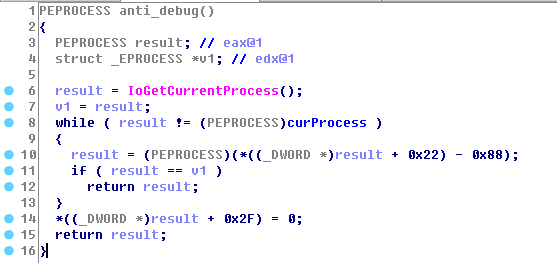
而这个检测触发的条件需要应用层程序发送一个控制码来触发:

分析一下应用层程序对应的控制码部分,一共有2个函数里发送了该控制码,以下是一个线程函数里专门每隔3秒钟发送一次该控制码进行反调试检测:
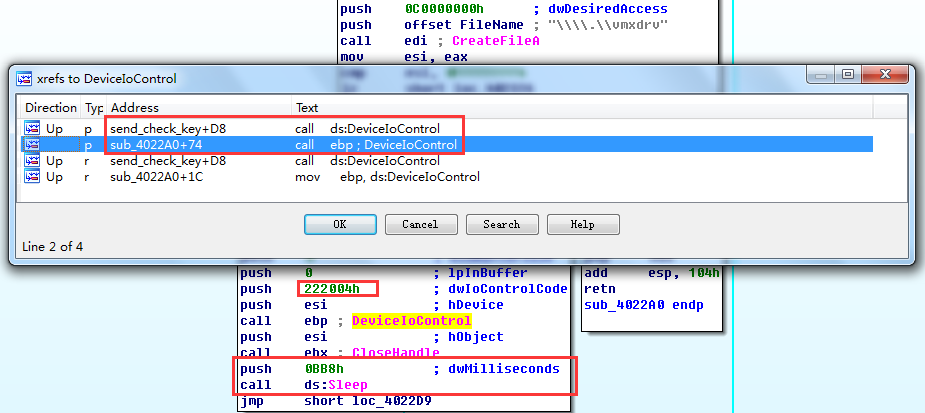
另外一处是在验证输入key时,在把key传给驱动程序前做了一次检测:
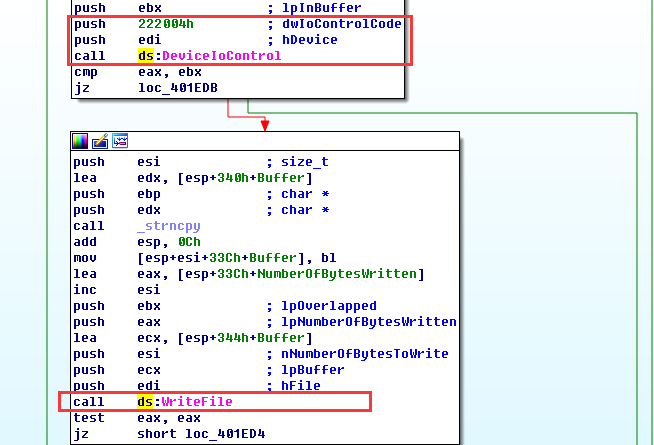
这样一来,要过反调试有两个选择,一种是patch应用层程序,把这两处发送的控制码的地方简单patch,但是有个弊端就是程序需至少发送一次该控制码给驱动层才能将bCheck值改成1,后面才会去正常验证key返回结果。这样的话就比较麻烦,所以用另外一种选择,修改驱动,在处理该控制码的位置将调用反调试函数的代码patch掉,然后修正一下校验和,在包含该驱动的exe文件对应处修改patch后的数据:
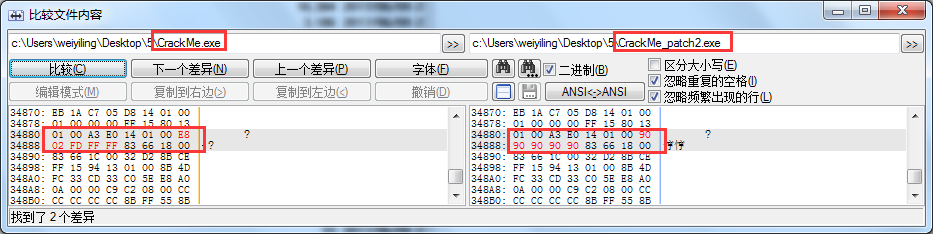
这样卸载驱动程序后重新运行程序,便可以高枕无忧的进行动态调试了。下面开始分析验证算法。
此时可以正常下断,GetWindowText*可以跟踪到输入串,发现检查了输入串的长度为6才进行校验:
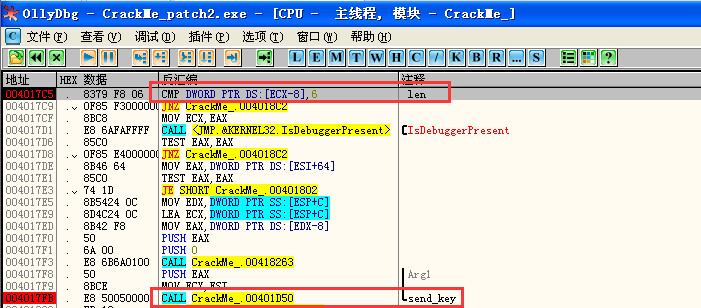
然后把输入串翻转一下直接发送给驱动程序:

驱动层计算完结果直接返回,看着像md5串:
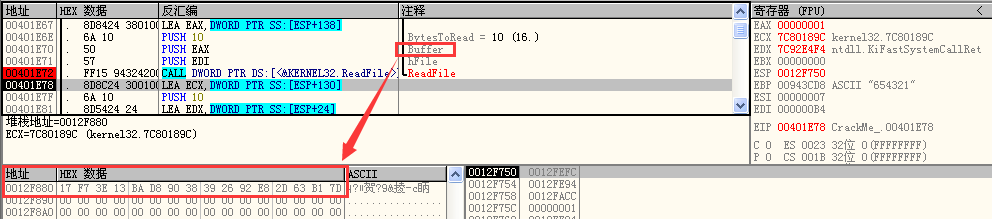
接着把该16进制串计算一下MD5:
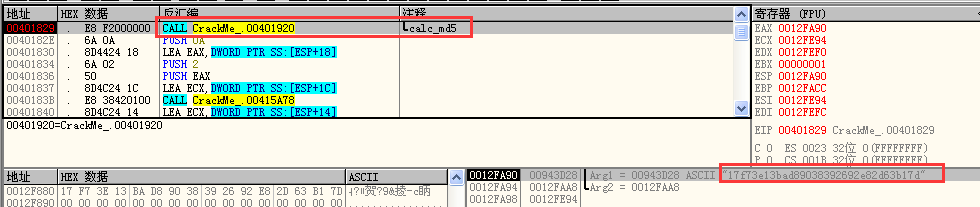
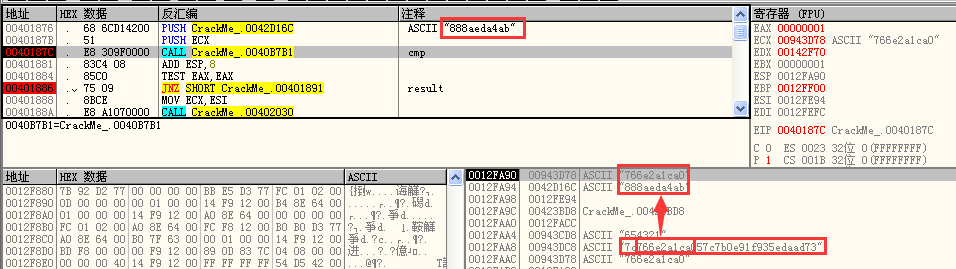
最后取其子串进行比较,一致的话则成功:
可见问题的关键在于把输入串传递给驱动进行计算的过程了,由于输入串长度为6比较小,比较容易进行暴力枚举进行破解,然后又有两个选择,一个是直接当驱动是个黑盒,在枚举过程中将字符串传给驱动去计算再返回校验,另一种就是去分析驱动的算法来提高暴力枚举的“效率”。本人尝试了两种方法,发现确实速度提供了不少,毕竟减少了通信的读写过程。上面提到,驱动返回的结果有点像md5串,一开始以为是修改后的md5算法,但是仔细过一遍应用层和驱动层的md5算法能够发现,其实算法是一致的,也就是都用的是md5算法,但是驱动层又另外对输入串进行了一次处理,导致返回的md5值并不是原输入串的md5:
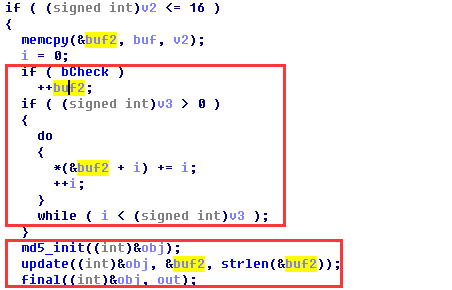
这样的话就清晰很多了,都是md5算法,枚举算法好办了,省去了和驱动通信的额外开销,可以专心的跑脚本了。。。贴个比较暴力的6层循环枚举(也可以修改一下分成6份开6个进程跑):
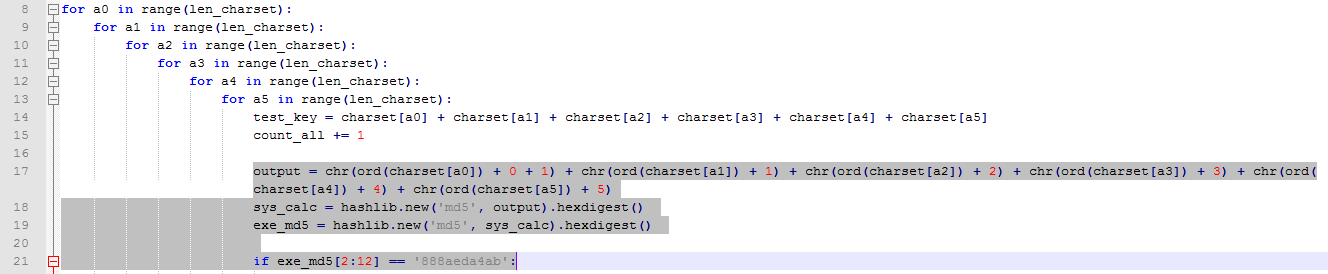
就这样吧,看装备看人品了哈。