正在下载:keygen.zip 腾讯游戏安全技术竞赛2017Round1
调试
程序无壳,可直接载入调试器或附加进行调试,试图断go的按钮事件的消息断点,失败了,好像窗口过程指向了奇怪的地址,也不懂做了什么保护:
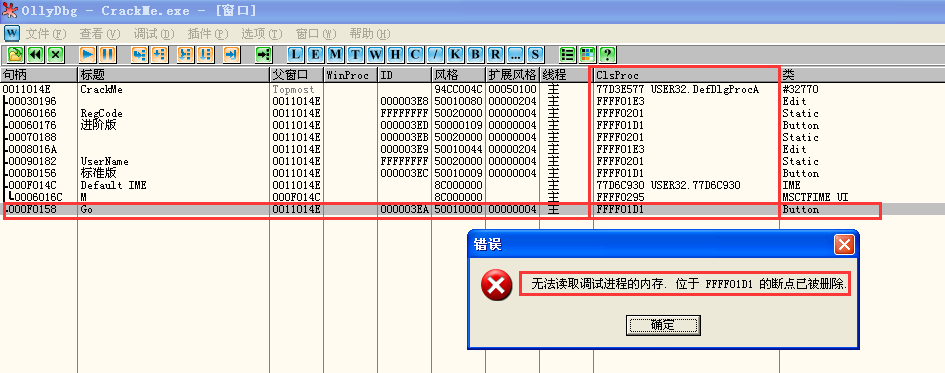
点击go按钮之前就进行内存搜索,发现用户名和注册码在验证前就被读到多个地址:
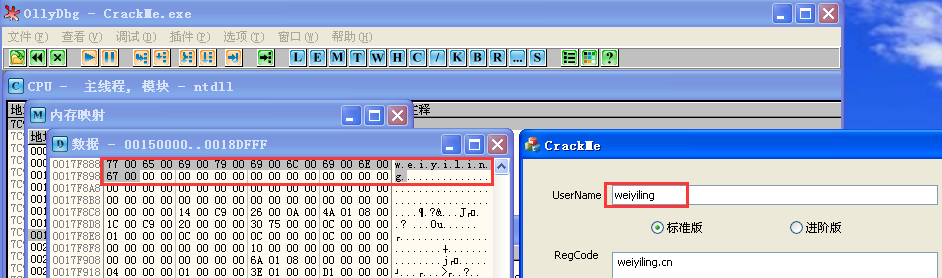
所以直接内存断这字符串不好跟踪到验证逻辑的地方,换种方法进行跟踪,对“GetDlgItem”或“SendMessageA”下断,点击go验证后中断,返回到用户代码就直接到了主验证函数:
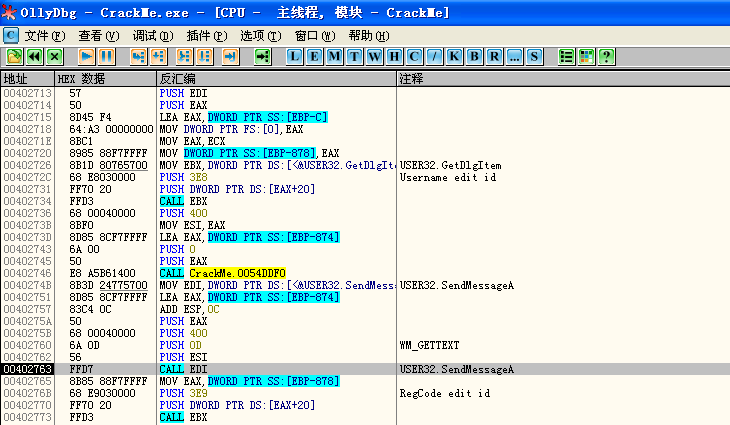
在这里可以观察到获取用户名和注册码后开始进行验证过程,下面结合IDA边进行逆向分析。
分析
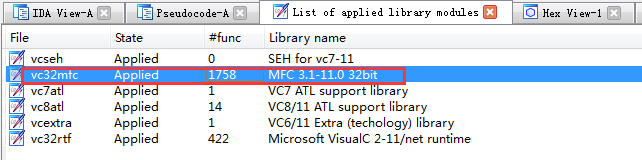
把程序拖到IDA里分析,由于是MFC程序,可以事先加载一下相关的sig,以便更好识别库代码:
然后根据上述调试跟踪到的位置,定位IDA里的验证函数,发现之后很容易就找到验证结果的点:
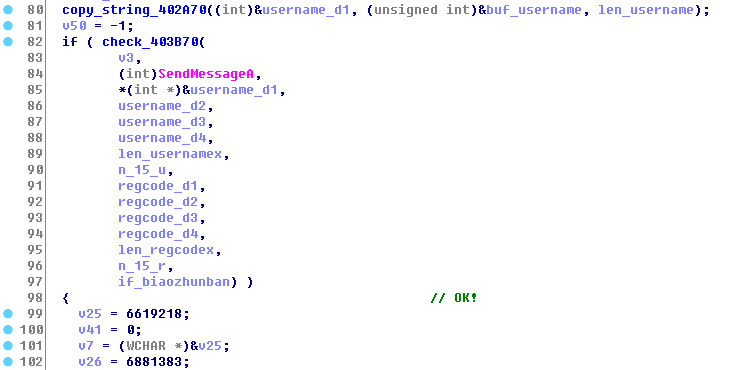
验证函数check_303b70成功后便验证通过,进入该函数后慢慢分析每个子函数的功能和作用,理解程序的流程:

分析后得出大概流程:即根据输入的用户名,以“-”为分隔符,需要分割成8个子串,每个子串的长度为4。然后判断选择用哪个版本的解密函数对注册码进行解密,之后就是将解密后的数据和8个子串一起做某些运算后判断是否验证成功。下面详细跟进每个子函数。
用户名合法性
首先检查输入的用户名是否合法,具体在check_username_4033A0,字符个数为39:
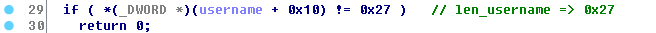
检查完字符数量后对输入字符进行大小写转换,将其中的大写字符统一转换成小写字符:
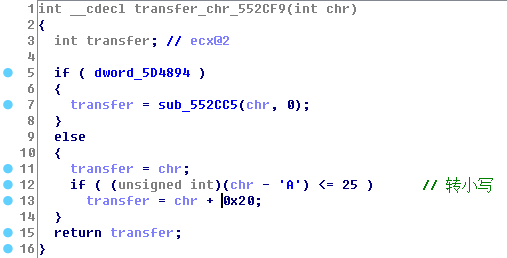
接着对用户名进行分割,分割符为“-”,分割后的子串存储在0x18字节的空间里,通过输入存储的总容量计算子串的数量,判断是否为8个子串,所以推出用户名包括7个“-”分隔符:

继续检查每个字符的合法性,判断是否包含在十六进制字符集:

到这里,可以确定用户名一共包含7个“-”分隔符,8个16进制子串(忽略大小写),但是并没有规定每个子串的长度。接着调用一个处理函数deal_username_4034E0,从该处理函数里可以推测出每个子串的长度。该函数对每个子串进行一系列的计算,计算结果分别保存到4个64位的数据块里,后面验证的时候将会用到。

注册码解密
接下来分析注册码部分。根据是否选定用标准版来决定用什么方式对输入的注册码进行解密,解密完成后判断解密是否成功以及解密后的数据长度是否为0x10来决定是否进行最后的验证:

也就是说,标准版和进阶版的主要区别就是对注册码的解密方式不同,后面的分析也能得出同一个用户名对应的注册码“源数据”在标准版和进阶版里其实是相同的,只不过加密后的形态不一样罢了。这里,先分析标准版的解密流程,对应的解密函数decode_regcode_b64_406040,是一个变种的base64加密。
函数一开始先取出base64的字符集映射表,该表和标准的base64不同:

检测输入的注册码是否都在规定的字符集里:

然后开始进行解密,每4个注册码字符为一组进行解码,每组里对每个字符查找对应映射表的索引位置,找到后增加了一个与标准base64不同的操作,把索引进行了右移和异或操作:
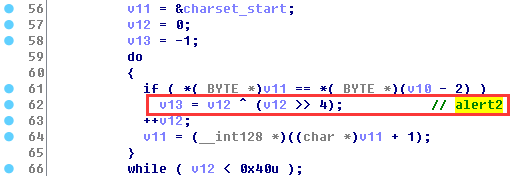
每组4个加密字符都找到对应索引后,要对应回加密前的3个字节原始数据,如果遇到下一个加密字符为“=”,就解密到当前位置为止:
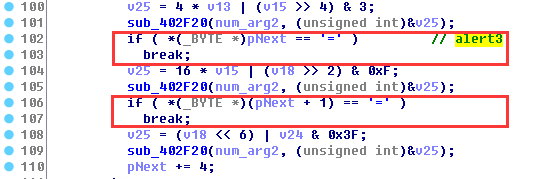
根据此函数的特点,后面编写注册机对标准base64代码进行修改,加解密函数的过程都要符合本函数,保证加解密前后一致。
注册码验证
最后对前两部分得到的计算后的用户名数据块和解密后的注册码数据块进行验证,验证成功便能成功,验证函数位于check_calc_403160:
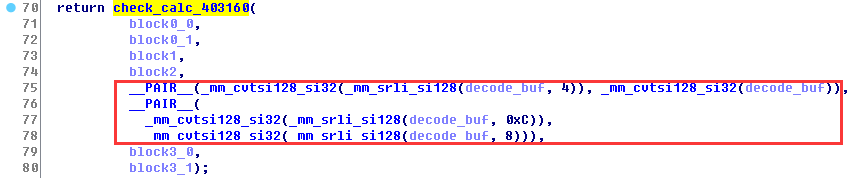
可以看出输入参数分别是4个用户名数据的block*和解密后的注册码数据decode_buf,进入内部的计算验证后返回0或1,验证的过程其实是检查是否满足一个二元二次方程组:

最后只需要把每个参数当成一个64位整型数据,求解方程的解decode_before8 和decode_after8就能得到解密后的注册码,根据加密方式加密回去就能得到需要的注册码。
注册机编写
由于学习逆向以来没有怎么写过一个真正的注册机,这题就认真写一个,当然进阶版没有实现,只实现了标准版的,采用MFC框架编写。下面直接贴关键代码,完整详见附件。
void Cqqyouxi_round1Dlg::OnBnClickedButtonMake()
{
// TODO: 在此添加控件通知处理程序代码
this->UpdateData(TRUE);
if ( m_cs_sn0.GetLength() != 4 || m_cs_sn1.GetLength() != 4
|| m_cs_sn2.GetLength() != 4 || m_cs_sn3.GetLength() != 4
|| m_cs_sn4.GetLength() != 4 || m_cs_sn5.GetLength() != 4
|| m_cs_sn6.GetLength() != 4 || m_cs_sn7.GetLength() != 4 )
{
this->MessageBox(_T("用户名子串长度不合法!"), _T("提示"));
return;
}
if (!check_chr(m_cs_sn0) || !check_chr(m_cs_sn1)
|| !check_chr(m_cs_sn2) || !check_chr(m_cs_sn3)
|| !check_chr(m_cs_sn4) || !check_chr(m_cs_sn5)
|| !check_chr(m_cs_sn6) || !check_chr(m_cs_sn7)
)
{
this->MessageBox(_T("用户名包含字符不合法!"), _T("提示"));
return;
}
CString sn = m_cs_sn0 + "-" + m_cs_sn1 + "-" + m_cs_sn2 + "-" + m_cs_sn3 + "-" + m_cs_sn4 + "-" + m_cs_sn5 + "-" + m_cs_sn6 + "-" + m_cs_sn7;
CString sn_old = sn;
sn.MakeLower();
USES_CONVERSION;
std::string username(W2A(sn));
//std::string username = "1111-2222-3333-4444-5555-6666-7777-8888";
std::vector<std::string> r_sn;
split(username, std::string("-"), &r_sn);
std::string sn0 = r_sn[0];
std::string sn1 = r_sn[1];
std::string sn2 = r_sn[2];
std::string sn3 = r_sn[3];
std::string sn4 = r_sn[4];
std::string sn5 = r_sn[5];
std::string sn6 = r_sn[6];
std::string sn7 = r_sn[7];
__int64 block0 = (sn0[0] * sn7[0] << 16) + (sn0[1] ^ sn7[1]) + (sn0[2] % (sn7[2] + 1) + 1) + (sn0[3] / (sn7[3] + 1));
__int64 block1 = ((sn1[0] ^ sn6[0]) << 16) + (sn1[1] % (sn6[1] + 3)) + (sn1[2] / (sn6[2] + 1) + 5) + (sn1[3] + sn6[3]);
__int64 block2 = ((sn2[0] / (sn5[0] + 3)) << 16) ^ (sn2[1] * sn5[1]) + (sn2[2] % (sn5[2] + 7) + 5) + (sn2[3] + sn5[3]);
__int64 block3 = ((sn3[0] + sn4[0]) << 16) * (sn3[1] / (sn4[1] + 2)) + (sn3[2] % (sn4[2] + 5) + 7) + (sn3[3] * sn4[3]);
__int64 n = block2 + (block1 + block0 * block3) * block3;
__int64 a = 1;
__int64 b = (-2) * block1 - 4 * block0 * block3;
__int64 c = block1 * block1 - 4 * block0 * block2 + 4 * block0 * n;
__int64 decode_before8 = 0;
__int64 decode_after8 = 0;
__int64 detar = b * b - 4 * a * c;
if(detar >= 0)
{
decode_before8 = (-b + sqrt((long double)detar)) / (2 * 1);
decode_after8 = n - decode_before8 * block3;
unsigned char buf_key[0x10] = {0};
memcpy(buf_key, &decode_before8, 8);
memcpy(buf_key + 8, &decode_after8, 8);
std::string encoded;
if(m_radio_check_sample->GetCheck() == 1)
{
encoded = base64_encode(buf_key, 0x10);
}
else
{
this->MessageBox(_T("该版本暂未实现!"), _T("提示"));
return;
}
m_cs_regcode = CString(encoded.c_str());
m_cs_regcode = CString(_T("UserName : ")) + sn_old + CString(_T("\r\nRegCode : ")) + m_cs_regcode + CString(_T("\r\n"));
this->UpdateData(FALSE);
}
else //方程无解
{
this->MessageBox(_T("该用户名无对应注册码,请更换!"), _T("提示"));
}
}
总结
根据对用户名合法性的检查、用户名数据的计算以及注册码解密、验证的过程进行详细的分析后,可以总结出标准版和进阶版的不同和联系,它们唯一的不同之处就是对验证成功的注册码源数据进行加解密的方式不一样,本文只对标准版的解密过程进行分析,该版本是变种的base64,主要修改了标准的base64的字符映射表以及映射索引。而注册码进行验证的过程是求解一元二次方程(或二元二次方程组)的过程,最后发现,输入的随机用户名总能使一元二次方程的求根判别式等于0,也就是说虽然是二次方程,但只有一个解。这个情况的原因没有细究,猜测可能是前面计算用户名数据的时候那个过程是事先设定好的一个拆分算式,才最后使得任意数据通过该算式后最后计算得到的判别式等于0,实现了用户名和注册码一一对应。